General API Information¶
This page contains general information and conventions used in version 2 of all the Metax REST and RPC API’s.
API root for latest version of the REST API is https://metax.fairdata.fi/rest/
API root for latest version of the RPC API is https://metax.fairdata.fi/rpc/
Important
v2 of the API is not considered to be backwards compatible with v1 API, even if some endpoints seemingly work fine when cross-using them. If a dataset is created or updated using the v2 API, then the dataset should never be modified again using the v1 API. A dataset can be retrieved from v1 API and modified using v2 API, but after that, v1 API should no longer be used. The biggest risk of cross-using the different API versions is accidentally adding or removing files from a dataset and causing new dataset versions to be created.
Swagger¶
Detailed documentation per API currently in swagger:
Swagger file in Github: this is the file to use when finding out what a specific API consumes or returns
Metax Data Model: A High Level View¶
A simplified data model of Metax internals, and the relations between the most relevant objects that can be interacted with using Metax API.
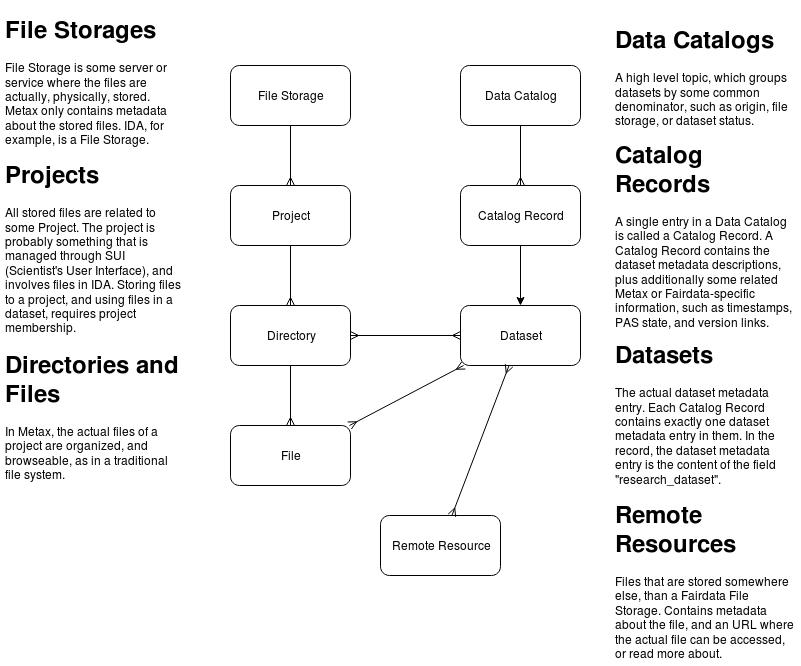
Important
Files do not physically reside in Metax. Only when files are frozen in the Fairdata IDA service, the metadata of the related files are pushed to Metax, so that it becomes accessible to other Fairdata services.
Relation of models in API to models in tietomallit.suomi.fi¶
Models in tietomallit.suomi.fi are logical models expressing the ‘fundamental requirements’ of the models in respect to their domain.
From the perspective of an API user, some fields or relations can be read-only for the user, can be modified only in certain situations, and the models can have additional implementation-specific fields added to them (such as user_created, date_modified, versioning related fields, etc.). To avoid writing lengthy API remarks in the tietomallit.suomi.fi schemas, the models in the swagger API documentation are described from the perspective of an API user, separately from the tietomallit.suomi.fi models. Since some models/relations are validated 1:1 against its tietomallit.suomi.fi schema file with very little special handling, some models are replaced with a link to tietomallit.suomi.fi, along with relevant information explained to the user about the handling of some fields in the model.
The schemas in tietomallit.suomi.fi are not usable as such, since the actual schemas used have some manual modification made in them due to tietomallit.suomi.fi not supporting some json schema features yet, such as oneOf relations. Because of that, to validate any payloads being sent to Metax, the actual schema files should be downloaded from the Metax API GET /rest/v2/schemas endpoint, or from Github from their respective branches. In the repositories, the schema files are located in src/metax_api/api/rest/v2/base/schemas. For metax.fairdata.fi, the files are in https://github.com/CSCfi/metax-api/tree/2025-08_2.8.6/src/metax_api/api/rest/v2/base/schemas.
API versioning¶
Other versions of the API can be accessed like https://metax.fairdata.fi/rest/v1/datasets or https://metax.fairdata.fi/rest/v2/datasets etc.
An URL of the form https://metax.fairdata.fi/rest/datasets (no API version specified) always points to the latest version.
API Authentication¶
Basic Authentication and Bearer Tokens are used for access control for certain APIs. Basic Authentication credentials are distributed only to known Fairdata services. End Users are able to utilize Bearer tokens in order to interact with certain APIs. Read more about End User authentication and token use at Authentication.
Write operations (POST, PUT, PATCH, DELETE) always require authentication. Some APIs require no authentication when reading (GET operations), while others do. Authentication-related errors will result in a HTTP 401 or 403 error.
Character encodings¶
All data that goes into and comes out of the API should be utf-8 encoded.
Behaviour of POST vs. PUT¶
POST is used for creating new resources, and for general requests to execute some specific actions, such as the APIs to flush records (testing environments).
PUT is used only for updating resources, it does not implicitly create a new resource if it did not exist. Instead, a 404 if returned if the resource being updated is not found.
Return codes¶
HTTP return codes are generally 200 OK, 201 Created, 204 No Content for successful operations.
Errors generally return 400 Bad Request, 403 Forbidden, 404 Not Found, or 412 Precondition Failed.
Excluding 404 and 403, errors should always be accompanied with a body describing the error. Examples:
# 400 bad request, an error with some field:
{
'preferred_identifier': ['already exists']
}
# 400 bad request, in case of a more general error:
{
'detail': ['error description']
}
Note
The error descriptions are in arrays, because there could conceivably be multiple different errors concerning a single field.
Last-Modified header in API responses¶
On GET, POST, PUT and PATCH operations, a Last-Modified HTTP header is added to the response. It is set and derived from the response if it contains a resource or resources that contain a timestamp for its last modification date (or in the absence of that, creation date is used). In case of bulk create and update operations, timestamp of the first item in the response is used.
Error Reporting¶
The API stores data about errors occurred during requests. The API GET /rest/v2/apierrors can be browsed by administrative users to browse and retrieve error details.
Whenever the API returns an error, included in the response should be a field called error_identifier, which identifies the stored error details in the system. When asking for support in times of trouble, providing the mentioned error_identifier will help greatly.
Caution
Administrative users: The error data contains the entire uploaded request payload data, as well as the response returned by the API. In monster bulk operations, those can amount to Very Big Files! Be sure to inspect the error first by browsing the list in GET /rest/v2/apierrors, and see if the error in question is a bulk operation (field bulk_request is present), and the amount of lines contained (field data_row_count), in order to make a more educated decision on how you want to view the detailed error contents from GET /rest/v2/apierrors/id (i.e. web browser vs some other tool…).
This API is readonly for all types of users.
Describing relations in objects¶
When creating or updating objects in any API, the primary method of referencing another object is by referring to it by its identifier field (a string), or the actual related object itself (JSON object), in the same format as they are sometimes returned by the API. In other words, the object being saved or updated can include relations in any of the following ways (CatalogRecord relations used as an example):
# describing relations in objects in request body
{
"data_catalog": "identifier:of:catalog",
"contract": "identifier:of:contract"
}
# or
{
"data_catalog": {
"catalog_json": {
"some_fields": 123
},
"other": "fields"
},
"contract": {
"contract_json": {
"stuff": 123
},
"important": "value"
}
}
Expanding relation objects in API responses
By default the API returns only very minimal information about relation objects - such as data_catalog or contract of a dataset - usually just fields id and identifier. The optional query parameter ?expand_relation=x,y,z can be passed for GET requests to return the full object instead.
Retrieving deleted objects¶
All standard GET list and detail API’s (such as GET /rest/v2/datasets, GET /rest/v2/datasets/<pid>) accept an optional query parameter ?removed=bool, which can be set to search results only from deleted records. More complex API’s, such as GET /rest/v2/datasets/<pid>/files accepts a different parameter to retrieve deleted files only, not to be confused with the general ?removed=bool parameter.
Restoring deleted objects is currently allowed by performing a PUT or a PATCH request together with ?removed=true parameter. However, by applying the previously described operation on a removed object, the object always becomes non-removed, which effectively means a removed object cannot be updated without restoring it simultaneously. Enabling to do this is up to a client, but the actual action is not prohibited by Metax. Whether this will be denied or changed in the future or not will be seen.
Conditional Updates¶
To prevent accidental updates of resources when the resource in Metax has been modified by someone else by the time your update lands, the If-Unmodified-Since header can be used to make the API raise an error in such occasion. Currently the use of this header is optional for clients.
The value of the If-Unmodified-Since header will be compared with the date_modified field of the resource, which is present in every type of resource, is read-only for the user, and automatically updated server side on every successful update-operation. If the version in Metax is not newer, the update will carry on normally. If the version in Metax is newer, the API will return HTTP 412 Precondition Failed. In this case the client should fetch the resource again, check for conflicts in their update, use the value of the new date_modified in the If-Unmodified-Since header, and try to update the resource again.
Conditional Updates in List Operations
Since in a list operation it doesn’t make sense to compare the last-changed-date of all resources to a single date, conditional writes during list updates work differently.
The If-Unmodified-Since header has to be present to signal that the dates of the resources being updated should be compared during the update. The value of the header itself is not checked, only that it is present. Then, the server will compare the value of the field date_modified of each row in the list vs. its counterpart currently on the server, and raises an error if the server version is newer. This means that for list updates, the field date_modified is required when the If-Unmodified-Since header is set, in addition to the actual field that is being updated. An error is raised if the date_modified field is missing in these cases. Mostly this detail is relevant for list PATCH updates, since PUT should usually have all fields present anyway. Note that if the resource has never been modified (only created), the field still has to be present, but its value should be null.
Possible errors resulting from the header check will be displayed in the list operation result along other errors.